如何預期DeepSeek傳言中的R2新模型
炒股就看金麒麟分析師研報,權威,專業,及時,全面,助您挖掘潛力主題機會!
信息平權
路透2月25日報道了DeepSeek可能在5月前發布r2。之前DeepSeek研究員Daya在2月初已經說過:RL還在早期,今年會看“顯著進步”(significant?progress)
其實在r1論文中也提到過:由于目前RL訓練數據還很少,R1的下個版本會大幅提升。

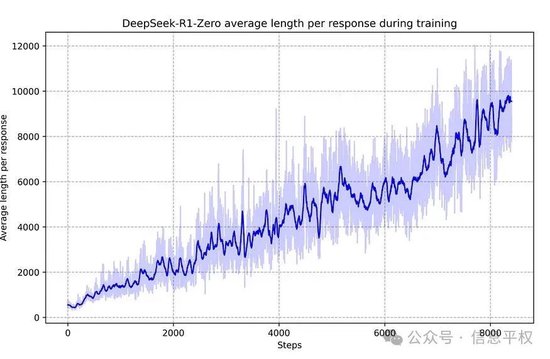
也就是r1論文中的下圖,以及論文所述:隨著RL數據的增加,模型不僅解決復雜推理任務的能力持續穩定提升,且會自然涌現出一些復雜行為能力,比如“反思”、“探索不同方法”。這些能力不是人類設計,而是隨著模型在RL環境中訓練,自然涌現的。
粗淺的理解,現在不需要算法上的巨大創新,按照目前路線+更多算力+DS如此強的infra能力,基于目前的V3基座模型,依然可以取得r2/r3。當看到RL提升邊際放緩,再基于新的基座V4,繼續做RL,進一步推進推理模型提升。也就是下面這張圖:(左腳踩右腳示意圖)
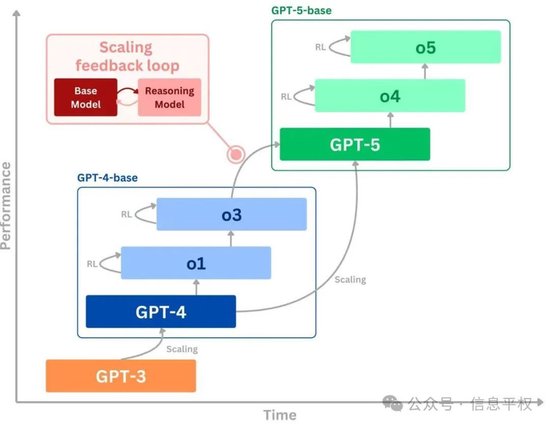
而參考OpenAI的路線圖,o3已經決定不發布完整模型,GPT-4.5也成了最后一個獨立發布的基座模型,意味著GPT-5(混合模型)開始,越來越黑盒。說白了,以后無論是基座模型還是推理模型本身,都是“原料”而不是“最終產品”,CloseAI和Anthropic一定會雪藏。
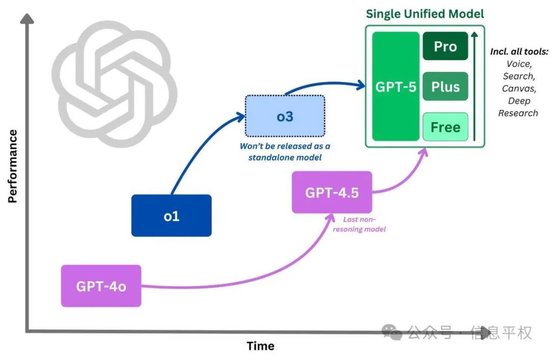
但DeepSeek要做的,就是在別人繼續閉源的時候,繼續開源。r2應該對標的是o3完整版,而V4至少應該對標GPT-4.5,基于V4+RL的模型,應該對標是未來的所謂“GPT-5”。因此合理預期應該是V4可能會加入多模態能力,但r系列依然是推理模型。且這個過程中,所有的“原料”全部開源,不僅原料開源,按照這次代碼五連發,連制造原材料的“配方”都直接開源。
這里面其實沒有什么DeepSeek不知道的秘密,甚至在infra層面遠超北美很多模型大廠。今天我們在討論的:DeepSeek甚至可能比英偉達更懂如何使用GPU。而所謂Research上的創新,OpenAI o系列的靈感也來自于早已發表的“開源”paper,疊加自己的算力優勢和工程探索實現。說到底沒人全靠自己閉門造車,都受益于全世界“開源”研究或實踐的喂養。
因此說回來,相比于r2,大家反而應該更期待V4,因為這打開了推理模型另一個level天花板,開辟的是另一條全新跑道。r2是時間表上確定的事情,而V4會是一個驚喜。這都會在今年發生。
(完)
文章內容有刪減
相關文章






最新評論